背景
之前支付宝可以分享红包,当收到红包的人点开你分享的支付宝口令之后,这个人就会有相应的红包额度。如果这个人在设定的时间内可以用掉这个额度,那你也相应会获得相同的红包数量。当时有人也因此发了笔大财,怎么做的呢?有人会通过群发大量的短信,当很多人收到短信然后会点进支付宝app,然后自己也会有相应的收益。
当然这篇文章的主题不是为了如何赚钱,而是我在思考类似的问题时,想到如何能获取大量的手机号码呢?爬虫一般会遇到信息安全问题,很多涉及个人隐私,所以这里的代码仅供参考。
解决方案
首先我找到了一个网站,手机全能查,按照这里的分类,应该是包含了全中国所有人的手机号码。作为示范,我先尝试爬取的是上海下面的所有手机号码。

根据上面三张图可以看到,三大运营商的上海地区号码都可以在这个链接下面找到.
我随便点击某个号码段,审查网页元素。
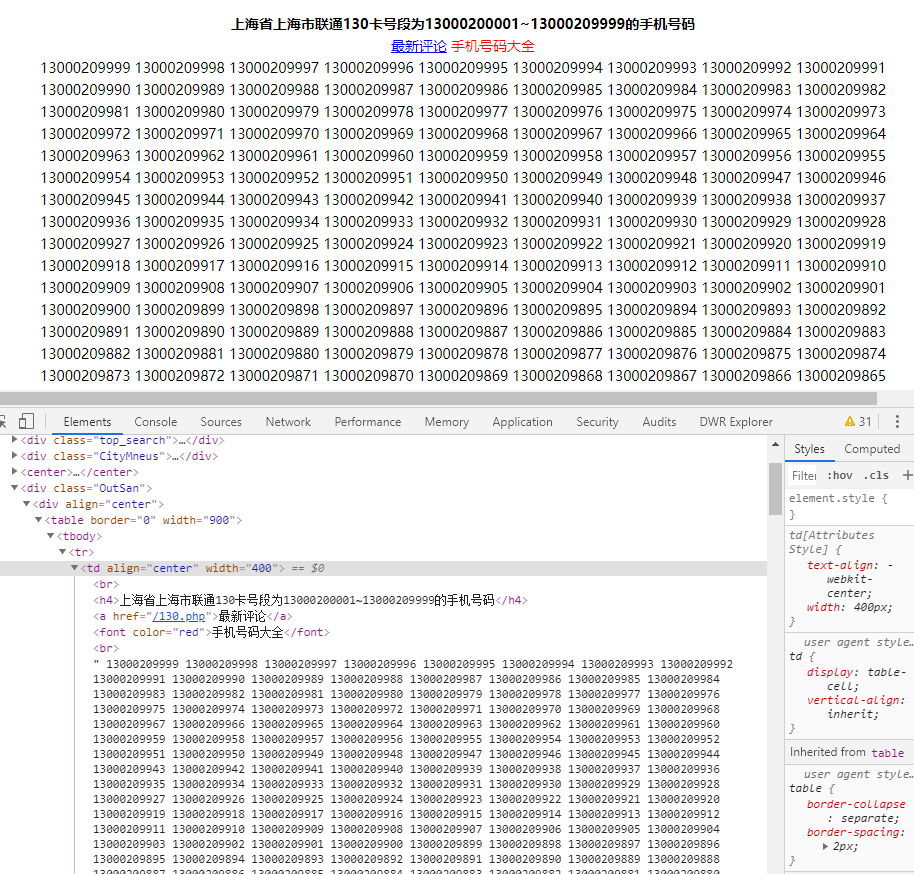
可以看到这是一个静态网页,所以解决方案有了:
- 获取不同号码段
- 在不同号码段下,请求页面,并通过正则表达式将号码解析出来
- 将号码存在文件中
OK,下面开始coding。
代码实现
对于爬虫来讲,Python是很好的工具,requests和BeautifulSoup都是Python爬虫中很实用的模块。代码也是按前面所述的步骤实现的。
- 获取不同号码段:
通过这个类去获取所有的号码段:
1 | class GetPhoneSegment(object): |
获取号码段的目的是为了拼装不同号码段所对应的URL。
- 在不同号码段下,请求页面,并通过正则表达式将号码解析出来
通过这个类获取不同的号码段下的所有号码,通过正则表达式解析所有的号码,最后将文件保存到硬盘上。
1 | class GetPhoneNumber(object): |
- 将号码存在文件中
在下面的主函数中可以看到,将获取到的手机号码存储在txt文本中。1
2
3
4
5
6
7
8
9
10
11
if __name__ == '__main__':
get_phone_seg = GetPhoneSegment()
seg_num_list = get_phone_seg.get_seg_num()
get_num = GetPhoneNumber()
print("号码段数量:" + str(len(seg_num_list)))
for seg_num in seg_num_list:
data = get_num.get_phone_num(seg_num)
fo = open(seg_num + '.txt', 'w') # a: 追加, w: 覆盖
fo.write(data)
fo.close()
跑起来!
为了验证代码可以正常运行, 直接运行看是否能够下载号码。由于是公司的电脑, 隐去了一些个人信息。 由下图可以看到, 上海市所有的号码段有5880个, 基本上一个号码段是9999个, 按照1万个计算, 上海市的号码数量是5880万个左右, 还是有点多的。
运行一段时间后, 可以看到文本文件中已经有不少号码了。当然我并没有把将近六千万的号码全部下载完……电脑吃不消,我也不需要这么多。当然为了避免总是在一个号码段下载号码, 可以加入随机函数, 比如说在一个号码段中取10个, 这样也有将近6万个号码,看个人需求。